
June 3-5, 2015 (iDigBio API Hackathon) – Team Integration blog, by Jorrit Poelen (Global Biotic Interactions), Dmitry Mozzherin (Global Names), Jon Lauters (U. of Colorado), Scott Bates (MacroFungi TCN, MacroAlgal TCN), Mike Trizna (Smithsonian), Nelson Rios (Tulane University, GEOLocate), Alex Thompson (iDigBio)
During the early stages of the hackathon, we talked about the proliferation of data and identifiers across all the databases, and the difficulties of making meaningful connections. For some members of our group, the difficulties were linking together related species, often based only on taxonomic name strings. For others, it was taking those name strings and making use of them to update collection taxonomies or create integrated views of the global taxonomic namespace. One member of our group, Dmitry, had already developed an algorithm for generating reliable identifiers for taxonomic names. We also talked about the difficulty of orchestrating the computation required for identifiers and linking. We decided that the best way to focus our efforts for the hackathon would be to build a series of Apache Spark jobs, to offload the complexity of building a scalable data pipeline, so we could focus only on the implementation. The planning for the activities of the interoperability group can be found in detail in our Hackathon Notes, and the designed workflow is shown below.
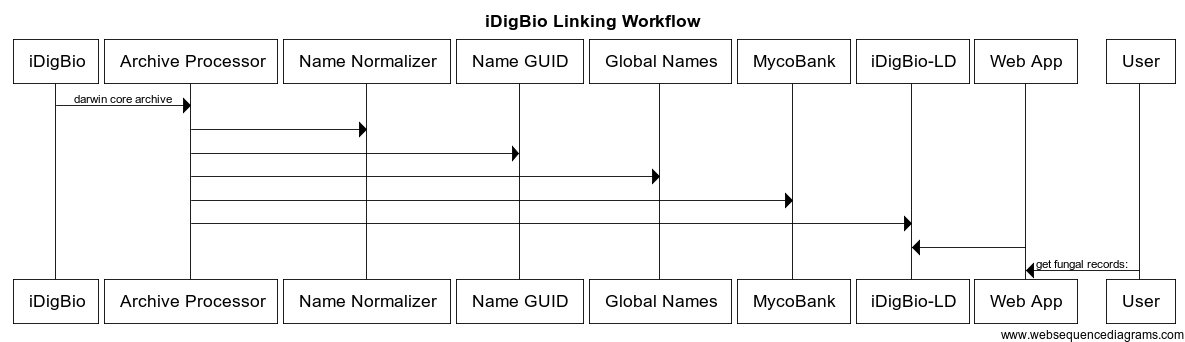
The target for the Spark installation was to build out jobs that could be used to augment the data in the existing iDigBio dataset with Global Names Architecture compatible name identifiers, as well as linking out to GenBank specimens, thanks to a regular expression provided by Mike Trizna (see below) to canonicalize the GenBank identifiers in iDigBio. The spark job created to process large amounts of iDigBio was able to scale from a laptop to a powerful 32 core server without any modifications to the job. This shows the benefits of Apache's Spark - after "sparkizing" the processing algorithms, large amounts of data can be processed on small (laptop) and large (server) servers, where spark figures out how to optimally use the available resources.
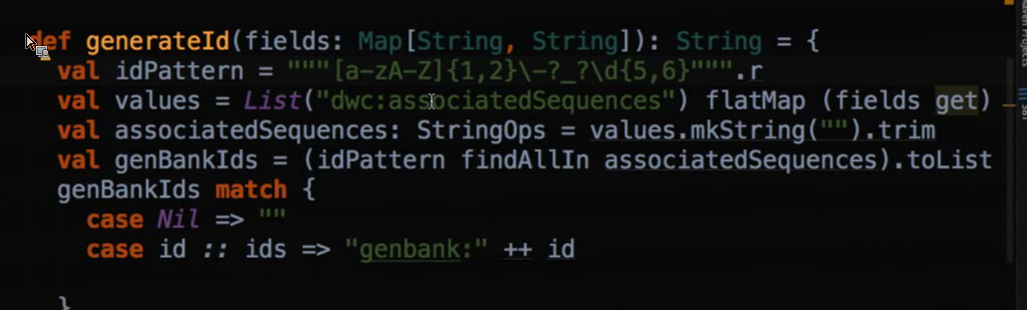
Spark jobs can be implemented in Scala, Java and Python. An early attempt to implement the job in Python caused the process to crash due to an out of memory issue. A later implementation in Scala was stable on both small (macbook) and large (32 core server) system. This seems to suggest that Python support might require additional configuration tweaking to get the jobs to complete reliably, while the Scala implementation work without any configuration changes.
These preliminary results suggest that Apache Spark is suitable for stable and performant processing of large (~GB) datasets like iDigBio. Our implementation algorithms that link iDigBio to Global Names and GenBank will help make it easier to discover iDigBio specimen records and their associations with other web-connected resources. The code for our spark implementation can be found at idigbio-spark.
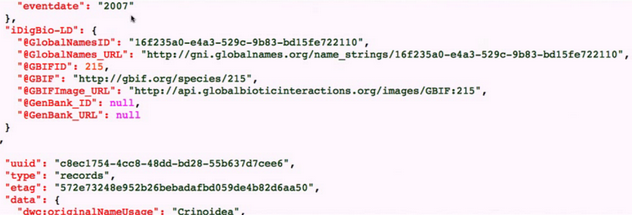
Jon Lauters was also able to take the output of the Spark jobs and create an overlay for the iDigbio Search API that augmented the available data with JSON-LD properties for automatic linked data integration, while the eventual target would probably be to get this integrated into the main iDigBio API codebase, he was able to get all the data loaded into a MongoDB instance, and build the overlay service without any need to modify . The code for the service can be found at iDigBio-LD, with a sample output below.
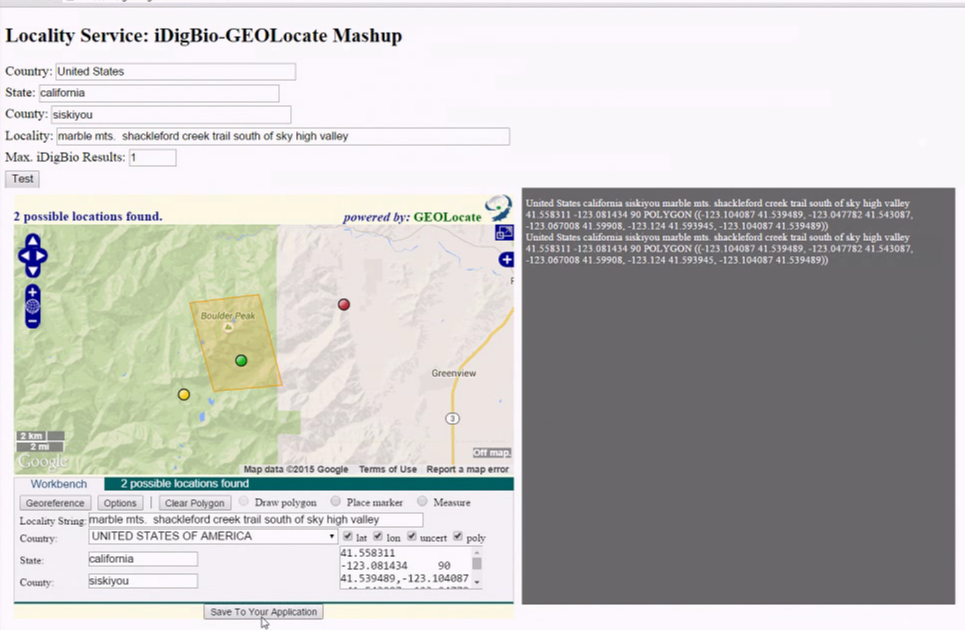
Integration between GEOLocate and iDigBio was developed by Nelson Rios, both to provide an overlay service to geo-reference idigbio records, and to build out geolocation services by utilizing the locality data already in iDigBio. One of the great challenges in this effort was to take advantage of georeference present in iDigBio without biasing GEOLocate with samples that introduce errors. Examples of these integrations can be found in github, and the web interface shown below.
Alex Thompson produced a simple twitter bot that uses the API and Python Client to send a picture of the specimens (shown below) within a bounding box when tweeted a location. It is currently running on the @idigbiobot twitter account, and the code is available on github.
Go back to read the other reports.